Intro
Hey all, been quite busy lately so didn’t get round to
blogging as much as I would like to. But hey ho, here I am :)
This time, I wanted to continue to work on the fuzzy-text-search blogpost of last time. In that blogpost, I indicated how the supplied fuzzy-text-search module I made, based on N-grams, could be used to help users of a website. For example, we can use it to create suggestive 404’s and provide searchterm suggestions when users mistype words.
This time, I wanted to continue to work on the fuzzy-text-search blogpost of last time. In that blogpost, I indicated how the supplied fuzzy-text-search module I made, based on N-grams, could be used to help users of a website. For example, we can use it to create suggestive 404’s and provide searchterm suggestions when users mistype words.
In the meantime, I’ve slightly updated the code and as a proof
of it actually working in practice, I’ve implemented it in a website I
made for an indie-band, see here: http://www.inpreviouschapters.com
Note that all the code is open-source, available at my
GitHub: https://github.com/HasanKaragulmez/FuzzyTextSearch
Not tied to Umbraco
Even though I’ve implemented this in an Umbraco-solution to
create suggestive 404´s and spellchecks in Umbraco, there’s actually nothing
inherently tied to Umbraco – you’re free to implement it in any solution you’d
like.
To make it somewhat less abstract, what I mean with
suggestive 404’s is for example when someone mistypes an url, or perhaps uses
an old link.
We can then help the user by checking all url’s and see if
we can make a suggestion as to what the user might have meant, rather than put our hands up in the air and give up. We still give a
404 Page Not Found-response, of course, for SEO purposes. If you´ve got a very high match-percentage you could
choose to do a 301-redirect instead of giving a 404-page, but that’s up to you.
Examples please!
In this example, I’ve navigated to a link which doesn’t
actually exist: http://www.inpreviouschapters.com/media/amsterdam-show
We then get a suggestive 404-page:
 |
| A suggestive 404-page |
For the search-functionality, we can do very quick search
corrections – for example, if you type "amstedam" instead of "amsteRdam":
 |
| Searchterm-suggestions in case of mistyped searchterms |
When we click on “amsterdam”, we re-do the Umbraco search
and actually get a result from Umbraco. We can then still be helpful by also supply a list of similar
words:
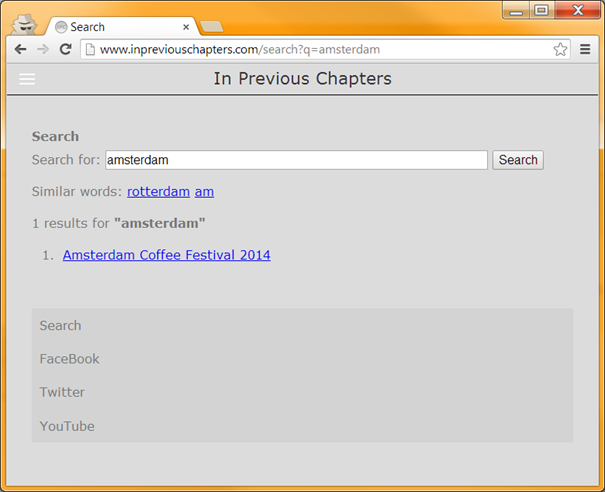 |
| Supplying a list of similar words, in case an Umbraco result has been found |
Of course, you can do similar things in Umbraco using
Examine and learning the Lucene.net syntax, but I really like the simplicity of
just using Umbraco.TypedSearch
Besides, it’s easy to augment the Umbraco results as we’ll
see below.
Implementing Suggestive 404’s
So, let’s see how we can easily add suggestive 404’s to Umbraco.
Firstly, we’ll of course need to make the
Karagulmez.Text.Fuzzy assemblies known into the Umbraco world. To do this, I´ve copied two .NET assemblies into the bin-folder, Karagulmez.Text.Fuzzy.DefaultProviders.dll and Karagulmez.Text.Fuzzy.dll, like so:
 |
| Assemblies go into the Umbraco bin-folder |
Note that you can find prebuild-assemblies on Github:
https://github.com/HasanKaragulmez/FuzzyTextSearch/tree/master/FuzzyTextSearchImplementor/AssemblyReferences
https://github.com/HasanKaragulmez/FuzzyTextSearch/tree/master/FuzzyTextSearchImplementor/AssemblyReferences
Congratulations, you’re done!
Well, almost - the following depends on how you code in Umbraco. I’ve decided to use
the App_Code-folder for Razor-helpers, and the Views-folder for the actual
View. This way, Umbraco and Razor facilitate creating clean-views, i.e:. not
stuffing your View full of program logic.
So, let’s see what we’ll put in the App-Code 404-page
helper, the most important bit is this:
//generic setting up
and configuring urls
public static IEnumerable<KeyValuePair<string, double>> SearchTerm(string searchTerm, List<string> urlsList)
{
var translateDict = new Dictionary<string, string>();
translateDict.Add("http(s)://{.*}/", string.Empty); //filter out the
domain, if it's there
translateDict.Add("/", string.Empty);
//Wrap these in a dictionary as a container
for a single object
Dictionary<string, object> initializationData = new Dictionary<string, object>();
initializationData.Add("filter", translateDict);
initializationData.Add("strings", urlsList);
//note that loading assemblies this way is
very very cheap
IFuzzyTextSearchManager
fuzzyTextSearchManager = new FuzzyTextSearch();
fuzzyTextSearchManager.InitializeConfiguration("Karagulmez.Text.Fuzzy.DefaultProviders",
"Karagulmez.Text.Fuzzy.DefaultProviders.FromInMemoryUrlsConfigurator",
/*System.Diagnostics.Stopwatch stopWatch =
new System.Diagnostics.Stopwatch();
stopWatch.Start();*/
int maxResults = 10;
IEnumerable<KeyValuePair<string, double>> searchResults =
fuzzyTextSearchManager.Search(searchTerm, maxResults);
/*stopWatch.Stop();*/
/* ( @stopWatch.ElapsedMilliseconds ms,
exact: @stopWatch.Elapsed.ToString())*/
return searchResults;
}
|
That’s not too hard is it?
With the supplied list of url’s (by doing it this way, we
can work completely platform-agnostic – we don’t care HOW the urls are
supplied) we can let the fuzzy-text-search modules do its stuff, and return a
result. Note that the result is a keyvalue-pair consisting of the result and
the matching percentage.
The filter is there to filter out stuff in the urls-list,
that we don’t want to use for matching – e.g. domains. If you want to filter
out specific words, or even translate some words into other words and thus
influence the results, you’re free to do so of course.
So, we package the data we want to use into a single Object,
and pass that into initializing the Karagulmez.Text.Fuzzy-code. We then request
the results. I’ve commented out some StopWatch code which you can use if you want to test how
long it takes in your scenario.
Note that I´ve done a pretty basic implementation; I´m not
caching any of the results or even the initialization of the
Karagulmez.Text.Fuzzy assemblies – you’re free to do so.
What this means in practice, is that first time
initialization is “slow” – around 50ms on my old laptop, then subsequent calls
only take a milisecond. At this shared hosting provider, it seems to be a bit
slower, at around 5-6ms. You’re encouraged to do your own testing of course,
but I think it’s save to say it’s unlikely to be a bottleneck.
Note btw that for supplying the list of url’s, I’ve actually
re-used code I wrote from the sitemap-creator by just calling the
Sitemap-helper from the 404 Page-helper. Easy peasy:
//umbraco-specific retrieval of urls public static List<string> GetSiteUrls(dynamic currentPage, dynamic umbraco) { var allSiteMapItems = SitemapHelpers.AllSitemapItems(currentPage, umbraco); var urlsList = new List<string>();
if( allSiteMapItems.Count > 0) { foreach(var sitemapItem in allSiteMapItems) { urlsList.Add(sitemapItem.Url); } }
return urlsList; } |
Finally, we just loop through the results and display them:
@helper FuzzySearchResults(IEnumerable<KeyValuePair<string, double>> searchResults)
{
var searchCount = searchResults.Count();
if (searchCount == 0)
{
<p>Why not start at the
<a href="/">homepage</a></p>
}
else //at least one
result
{
var firstResultUrl = searchResults.First().Key;
<p>Did you mean: <a href="@firstResultUrl">@firstResultUrl</a></p>
if(searchCount == 2)
{
var kvp = searchResults.ElementAt(1);
<p>Or perhaps <a href="@kvp.Key">@kvp.Key</a>?</p>
}
else if(searchCount > 2)
{
<p>Or perhaps one of
these:</p>
<ul>
@foreach(KeyValuePair<string, double> kvp in searchResults.Skip(1))
{
<li><a href="@kvp.Key">@kvp.Key</a></li>
}
</ul>
}
}
}
|
Ok, so let’s go back to the View, there’s actually not that much to do:
@inherits Umbraco.Web.Mvc.UmbracoTemplatePage
@{
Layout = "Masterpage.cshtml";
}
@AppHelpers.PageTitle(CurrentPage)
<p>Sorry, the page @(HttpContext.Current.Request.Url.AbsolutePath) does not exist.</p>
@{
var searchTerm = HttpContext.Current.Request.Url.AbsolutePath;
var urlsList = Page404Helpers.GetSiteUrls(CurrentPage, Umbraco);
var searchResults = Page404Helpers.SearchTerm(searchTerm, urlsList);
@Page404Helpers.FuzzySearchResults(searchResults);
} |
That’s it! Told you it would be easy ;)
So, now, whenever we hit the 404-page, we can do a lookup and see if we can help the user, say if we mistype “media”
So, now, whenever we hit the 404-page, we can do a lookup and see if we can help the user, say if we mistype “media”
 |
| Suggestive 404 with another url |
Try it yourself: http://www.inpreviouschapters.com/mdia
Adding Searchterm-correction for Search
Ok, let’s look at the next functionality: helping the user
in case it mistyped words into the searchbox. There are a couple of ways to do this, as always. I
wanted to peek into the Lucene-index at first, and re-use all the words it
indexed.
However, this turned out more work and diving into Lucene than I
wanted. It *has* to be simple.
I’ve taken the approach to build an index of all the words
in the website, and then use that as a dictionary for word-correction. I think
this is a sound approach, as only the words which actually occur on the website
should actually have a search result. Sounds logical right? :)
You might think that there are a lot words in your website,
but note that only the amount of *unique* words matter (case-insensitve), not
the total amount of words. This means that we can process pretty quickly, even
if the number of words on a website increases steadily.
In a test I’ve done with a text-file upto 1MB (that is *a
lot* of text, I can assure you), I came to the following result:
 |
| Relation of words and unique words based on a whole lot of Internet articles |
You can run this test yourself with the test-program
FuzzyTextSearchImplementor, code is at: https://github.com/HasanKaragulmez/FuzzyTextSearch/tree/master/FuzzyTextSearchImplementor
Textfiles at various file-sizes are included as well.
Ok, so now that we understand a bit of the background, let’s
get our hands dirty and see what we need to do to accomplish this.
Also here, we seperate the code in pure code, defined as
Razor-functions and helpers in App_Code, and the view in… well, the
View-folder.
The code for getting the list of search suggestions is even
simpler than the suggestive 404-code.
Let’s look at the code first:
public static IEnumerable<FuzzySearchResults> FuzzySearchText(string searchTerm, string allText, int maxResults)
{
if(string.IsNullOrEmpty(searchTerm))
{
return null;
}
IFuzzyTextSearchManager
fuzzyTextSearchManager = new FuzzyTextSearch();
fuzzyTextSearchManager.InitializeConfiguration("Karagulmez.Text.Fuzzy.DefaultProviders", "Karagulmez.Text.Fuzzy.DefaultProviders.FromInMemoryTextItemsConfigurator", allText);
var splittedSearchTerms = searchTerm.Split(' ');
var allSearchResults = new List<IEnumerable<KeyValuePair<string, double>>>();
foreach(var term in splittedSearchTerms)
{
allSearchResults.Add(fuzzyTextSearchManager.Search(term, maxResults));
}
return allSearchResults;
}
|
As before, we get all the text we want to use for indexing,
initialize the Karagulmez.Text.Fuzzy-code, and get the results. Note here, that
I’ve gone one step further, and added support for correcting multiple words in one
go, in case the user types in multiple words (hence the foreach-loop at the
end).
Also note that the implementation is very straightforward,
I don’t cache any instances or text, even though I easily could have done so.
In this case, it doesn’t pose any problem.
So, how did we get all the text?
As said earlier, we just use all the words in the website,
as those are the words which will create a search-result.
With Umbraco, you can do this in a couple of lines of code.
public static string GetAllSiteText(dynamic currentPage, dynamic umbraco, List<string> forProperties)
{
var allSiteMapItems = SitemapHelpers.AllSitemapItems(currentPage, umbraco);
var bufferStringBuilder = new System.Text.StringBuilder();
foreach(var item in allSiteMapItems)
{
//only specific
properties
foreach(var searchProp in forProperties)
{
var propValue = item.PageNode.GetPropertyValue(searchProp);
if(propValue != null)
{
bufferStringBuilder.Append(propValue + " ");
}
}
}
var result = bufferStringBuilder.Replace(" ", string.Empty).ToString();
return result;
}
|
Note, again, it doesn’t matter where you get the text from –
if you want to load it from an in-memory cache, file on disk, property from a
page, whatever – it doesn’t matter, do what you think is best. This is just the
way I’ve done it.
The rest of the code is just logic for presenting the data
we get back. For example, if there is one search-term entered, we look if there
are search-suggestions and present it. If a sentence has been entered, we do a
lookup for each word, re-assemble the sentence, and present the corrected words
in italic.
Let’s see what this looks like:
Correcting one word – note how the default usage of Umbraco.TypedSearch
doesn’t find *any* results, even though we’ve only missed one letter:
 |
| Mistyped a single letter but the default Umbraco.TypedSearch still doesn't find any results |
Result after correcting:
 |
| Bingo. If we click the "amsterdam" search result we get a result Umbraco.TypedSearch |
Correcting multiple words in one go – note how the corrected
words are italic:
 |
| Able to correct multiple words in a sentence. Corrected words are italic. |
Umbraco result after fix, note how the search result “Amsterdam
Coffee Festival” is suddenly introduced:
 |
| Result after clicking the corrected result. Note how the results have changed for the better. |
If you look at inpreviouschapters.com,
you can actually inspect the search results a bit.
I’ve added tooltips for the search suggestions in case of
single terms:
 |
| With tooltips you can see what the matching-percentage is for the searchterm-candidate |
If you inspect the source, you can see an html-comment which
shows how long it took to generate the search results:
 |
| The HTML-source of inpreviouschapters.com displays how long the search took. |
If the site hasn’t been touched in a while, and memory has
been offloaded, note that the initialing-phase can take up to about 50ms on
this hoster.
Conclusion
We’ve seen that with a little bit of work, we can easily
create suggestive 404’s and augment the search functionality, without the need
for learning complex Lucene-queries.
Not bad for just a little bit of work :)
Remember that:
- All the code is open-source at my Github: https://github.com/HasanKaragulmez/FuzzyTextSearch
- Notably, the test program shows how to use the code, and
includes a console-program which you can use to see how quick it runs on your
machine - including test text-files:
https://github.com/HasanKaragulmez/FuzzyTextSearch/tree/master/FuzzyTextSearchImplementor - How these projects work together is explained at my previous
blogpost:
http://hasankaragulmez.blogspot.nl/2013/12/url-and-text-suggestion-correction.html - You can try out and play with the 404-code and searchterm-correction at
this website I made (and perhaps buy their EP if you like their music and
support indie-bands):
http://www.inpreviouschapters.com
Note that currently there is not a lot of text available, and of course, sometimes the results won’t be what you’d expect – it’s fuzzy-text searching after all ;)
That’s it!
If you try it out, or have any questions, suggestions,
feedback and/or constructive criticism - please let me know!
No comments:
Post a Comment